18/01/2022
In the last 15 years, Artificial Intelligence has gone from a relative scientific obscurity to infiltrating almost every aspect of our day-to-day lives. The rapid growth can largely be attributed to improvements in the processing speed of modern computers, and the massive amounts of data that we now produce. This data provides an abundance of training material for many AI algorithms. Despite its adoption across a wide variety of industries, AI can be a challenging topic to understand and explanations can often be full of jargon. In this insight, we will aim to demystify AI and explain some of the commonly used concepts underpinning its implementation.
What is AI?
The name “Artificial Intelligence” goes some way to providing the fundamental definition of AI. The exact definition of AI is still the topic of some debate, but in general at its core AI is a branch of computer science that aims to replicate or simulate human intelligence in machines. We can think of AI as the umbrella term that encompasses all the various algorithms and programs that are designed to perform tasks that, typically, would otherwise require a human to perform.
When many of us hear the words “Artificial Intelligence”, we can’t help picturing scenes from science-fiction films featuring hyper-intelligent machines vying for world domination. The reality is, thankfully, much more benign but also somewhat more nuanced. In fact, AI can generally be split into two categories – “Narrow AI” and “Artificial General Intelligence (AGI)”. The former of these, narrow AI, is the category that includes all of the AI technology with which we have become so familiar.
Narrow AI, also referred to as “Weak” AI is a term used to describe AI systems that are designed to perform very specific tasks very well, and therefore tend to be highly constrained. Narrow AI systems can appear highly intelligent. A prime example is the AlphaGo® program developed by Alphabet subsidiary Deepmind, which in 2016 made headlines by beating professional Go player Lee Seedol in a best-of-5 match. However, as impressive as this achievement may be, playing Go is all the program is designed for, and the only thing that it is able to do. Other well-known examples of narrow AI include virtual assistants such as Siri® and Alexa®, autonomous vehicles, and face recognition software.
On the other hand, AGI is the form of AI we typically see depicted in Sci-fi movies. Also known as “Strong AI”, it refers to AI systems that can think critically, problem-solve, and react like human beings. To date, we haven’t see any strong AI systems in the real world.
Common Terms:
Machine learning is a term used to describe a group of algorithms that form a subset of AI. Broadly speaking, machine learning refers to the ability of a machine to alter its own structure, programming, or data, based on its received inputs or external stimuli, in such a manner that its expected future performance improves. Machine learning algorithms are algorithms within the field of computer science that perform complex tasks by iteratively changing their own model parameters based on continuous assessment of their performance.
Generally, the “learning” component of machine learning algorithms will always share these three recognisable features:
- An output/goal: This seems obvious, but all machine learning algorithms are designed to perform a certain task. Typically, they are used to predict, or classify, something based on existing data. For example, an algorithm may be designed to predict the efficacy of a therapy based on previous trial data, or classify tissue types in an X-ray image.
- A performance metric: If an algorithm is to “learn” and get better at performing its intended task, then it follows that the algorithm needs to have some idea of how well it is performing. Sometimes referred to as the “cost function” or “loss function”, the performance metric typically aims to summarise the current overall performance of the algorithm as a single number.
- An optimisation process: The optimisation process takes the performance metric and uses it to work out which parameters of the machine learning algorithm should be adjusted, and by how much, in order to improve performance. A common example of an optimisation process is called “Gradient Descent” and is often applied to neural networks.
(Artificial) Neural Networks form the basis of a form of machine learning algorithm, where the structure is loosely based on the structure of a human brain. Artificial neural networks receive data, mathematically process the data and output data and can be trained to recognise patterns in data so that they can be used to predict the output for similar input data.
Neural networks are similar to the human brain, in that they are made up of layers of artificial neurons which are connected to each other. The neural network comprises an input layer, an output layer, and “hidden” layers in-between, where it’s the hidden layers which carry out the majority of the computation.
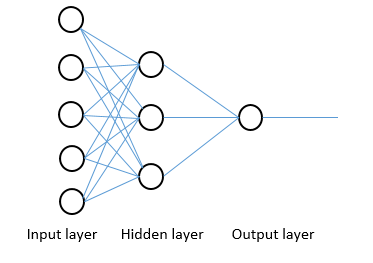
A schematic diagram showing the structure of a simple neural network having an input layer with 5 nodes, one hidden layer with 3 nodes, and an output layer with a single output node.
Each “neuron” in a layer may be connected to several neurons in the layer beneath it, from which it receives data, and connected to several neurons in the layer above it, to which it sends data. For each of its incoming connections, the node assigns a weight, where the higher the weight, the more influence the node has on another, which mimics how biological brain cells trigger one another across synapses.
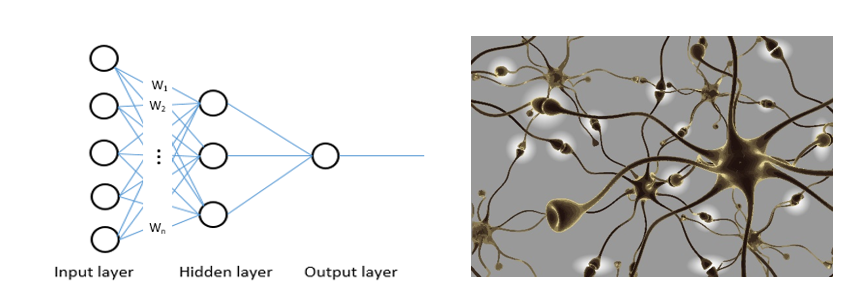
The interconnected network of nodes in a neural network is comparable to the interconnected network of neurons found in the human brain. The manner in which the weights (w1, w2 etc.) in a neural network are increased between two strongly related nodes mimics the way commonly used neural pathways in the brain become stronger over time.
Training a neural network refers to determining the best set of model parameters for maximising the neural network’s performance. As discussed above, training a neural network involves applying some form of optimisation process in order to improve a performance metric such that the neural network gets better at performing it’s intended purpose. The parameters of a neural network that are adjusted are it’s weights (the strength of the links between nodes) and biases (a threshold associated with each node that affects how easily the node becomes active). The weights of a neural network with hidden layers are very interdependent, as changing the weight of one neuron will affect the neurons in the following layers which depend on the neuron whose weight has changed. Therefore, determining the best set of weights for all of the neurons in the neural network is not achievable by optimising one weight at a time, and instead the entire space of possible weight combinations must be considered simultaneously.
To train the data, optimisation of the weight set must be achieved. There are different possible optimisation techniques which may be used to do this. One example is to repeatedly use the network on different examples of input data, and the weights adjusted to minimise the error in the network’s output, compared to the expected output.
Deep Learning is a subset of machine learning which uses neural networks with a large number of hidden layers. Deep learning models are often used to identify patterns in feature-rich data that might not be obvious to a human. They can be used to classify data by comparing new information to known patterns. Deep learning is defined as a neural network with at least two hidden layers. More layers in a network enable the network to perform more complex calculations, and find more nuanced patterns in data with lots of variables. For example, to categorise an image as a dog or a cat correctly, a conventional “shallow” neural network must first be taught what features differentiate a cat and dog, for example their facial structure and the shape of their tail, typically using hand-annotated training data as a ground truth to train the network on. In this respect, when implementing a shallow neural network, typically the user will have some expectation that their input features are mathematically related to the output. The neural network uses optimisation to identify the nature of that relationship. On the other hand, deep learning networks can taking seemingly unstructured, highly complex data with many variables as input data, and uses optimisation to identify patterns in the data and find a mathematical relationship that predicts the output for any future input.
Although deep learning has many applications, it also has a number of limitations, meaning that it is not the answer to solving everything. Firstly, deep learning requires a huge amount of training data, to be decently accurate. With a large number of hidden layers within the network, the optimal weight for the pathways between points (“nodes”) in the network is dependent on a large number of contributing nodes. To make the neural network sufficiently accurate, a huge amount of data is required to train the network, the training is computationally intensive and takes a long time.
There are numerous types of neural network such as convolutional neural networks (CNN) and autoencoders, details of which are beyond the scope of this introduction. One role of the AI implementer is to select the most appropriate type and scale of network for the AI so that it can achieve its purpose.
We hope we have shed light on some commonly-used AI buzzwords and given the reader a feel for what AI is and the basic principles involved in its implementation. If you would like to learn more about how AI is dealt with in the patent industry, take a look at our recent article about the challenges of, and opportunities for, patenting AI, or check out our recent AI in IP newsletter.
This article is for general information only. Its content is not a statement of the law on any subject and does not constitute advice. Please contact Reddie & Grose LLP for advice before taking any action in reliance on it.

